一、c语言导学与数据类型、数据输入输出
一、c语言导学与数据类型、数据输入输出
1导学
1.1前言
先有高级语言 ALGOL 60(简称 A 语言),后来它经过简化变为 BCPL 语言(改进后称为 B 语言),而 C语言是在 B 语言的基础之上发展而来的,所以就称为 C 语言。因此,世界上的第一个 C 语言编译器是用 B 语言编写的。目前,主流的编译器是 GCC 编译器(Mac 计算机也使用这个编译器),1972 年,Dennis M. Ritchie 在 B 语言的基础上最终设计出了一种新的语言,他以 BCPL 的第二个字母作为这种语言的名字,这就是 C 语言。
1.2程序-编译与调试
程序的作用是完成某种计算
两个斜杠“//”后面的内容为代码注释,程序编译时不会编译到程序中。
#include <stdio.h> //头文件
int main() { //入口函数
printf("Hello world"); //函数内的代码内容
return 0; //返回值
}
main 是主函数名,int 是函数返回值类型。每个 C 程序有且只能有一个主函数 main,程序从 main 函数开始执行。花括号{}是函数开始和结束的标志,不可省略。每个 C 语句均以半角分号结束。
使用标准库函数时应在程序开头一行书写如下内容:
#include <stdio.h> //printf 函数需要使用该头文件
2数据类型、数据输入输出
2.1数据类型分类
%% graph定义了这是流程图,方向从左到右 graph LR i(数据类型) i1(基本类型) i2(构造类型) i3(指针类型) i4(空类型
viod) i11(整型int) i12(浮点型float) i13(字符型char) i21(["数组[ ]"]) i22(结构体struct) i ---i1 i --- i2 i --- i3 i --- i4 i1 --- i11 i1 --- i12 i1 --- i13 i2 --- i21 i2 --- i22
2.2c语言关键字
| auto | const | double | float | int | short | struct | unsigned |
|---|---|---|---|---|---|---|---|
| break | continue | else | for | long | signed | switch | void |
| case | default | enum | goto | register | sizeof | typedef | volatile |
| char | do | extern | if | return | static | union | while |
避免命名变量时与关键字重名(不用记)
2.3常量
常量是指在程序运行过程中,其值不发生变化的量,常量可以分为整型、实型(也称浮点型)、字符型和字符串型
- 整型 100,125,-100,0
- 实型 3.14,0.125,-3.789
- 字符型 ‘a’,’b’,’2’
- 字符串型 “a”,”ab”,”1c34”
2.4变量
变量代表内存中具有特定属性的一个存储单元,它用来存放数据,即变量的值。这些值在程序的执行过程中是可以改变的。
变量名实际上以一个名字代表一个对应的存储单元地址, 编译、链接程序时, 由编译系统为每个变量名分配对应的内存地址(就是空间).从变量中取值实际上是通过变量名找到内存中存储单元的地址,并从该存储单元中读取数据。
变量的命名规定如下: C语言规定标识符只能由字母、数字和下画线三种字符组成, 并且第一个字符必须为字母或下画线. 例如,
sum, _total, month, Student_name, lotus_1_2_3, BASIC, li_ling//正确的
M. D. John, ¥123,3D64, a>b //错误的
编译系统认为大写字母和小写字母是不同的字符,C语言要求对所有用到的变量做强制定义, 即“先定义, 后使用”。同时在选择变量名和其他标识符时, 应尽量做到“见名知意”,即选择具有含义的英文单词(或其缩写) 作为标识符。注意, 变量名不能与关键字同名!
2.5整型数据
2.5.1符号常量
定义一个整型变量时要用到关键字int
#include <stdio.h>
#define PI 3+2
int main()
{
int i = PI*2;
printf("i=%d\n",i);
return 0;
}
最终输出结果为7,符号常量PI是直接替换的效果(3+2*2=7)
2.5.2整型变量
只掌握int即可应对初试,后面高级阶段讲解不同类型整型变量,int变量是4个字节

2.6浮点型数据
2.6.1浮点型常量
表示浮点型常量的形式有俩种,e代表10的幂次,幂次可正可负
表示浮点型常量的俩种形式
| 小数形式 | 0.123 |
|---|---|
| 指数形式 | 3e-3(为3X10⁻³,次方,即0.003) |
注意: 字母e(或E) 之前必须有数字, 且e后面的指数必须为整数.
正确示例: 1e3、1.8e-3、-123e-6、-.1e-3。
错误示例: e3、2.1e3.5、.e3、e.
2.6.2浮点型变量
通过 float f来定义浮点变量, f占用4个字节的空间
2.7字符型数据
2.7.1字符型常量
用单引号括起来的一个字符是字符型常量, 且只能包含一个字符! 例如, ‘a’、’A’、’1’、’’是正确的字符型常量, 而’abc’、”a”、””是错误的字符型常量。下表中给出了各种转义字符及其作用。以“\”开头的特殊字符称为转义字符, 转义字符用来表示回车、退格等功能键。
| 转义字符 | 作用 |
|---|---|
| \n | 换行 |
| \b | 退格 |
| \\ | 反斜杠 |
2.7.2 字符数据在内存中的储存形式及使用方法
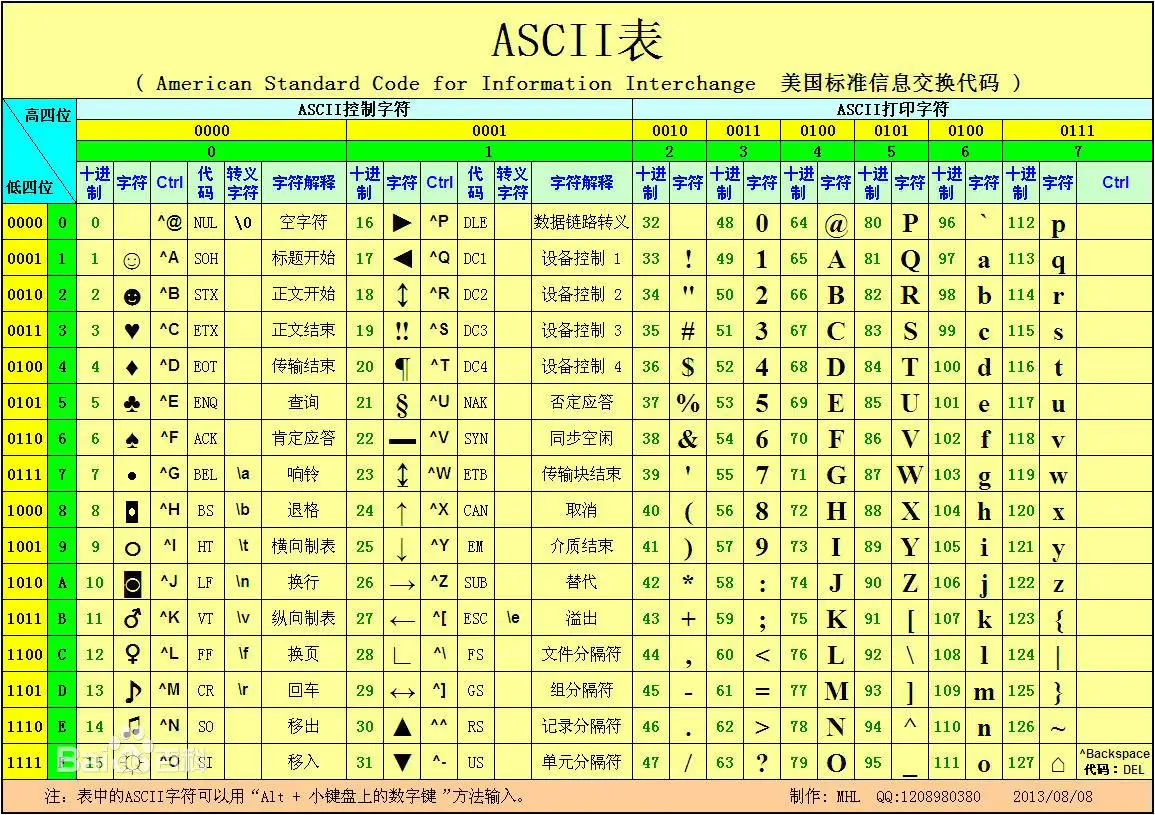
字符型变量使用关键字 char进行定义, 一个字符型变量占用1字节大小的空间。一个字符常量存放到一个字符型变量中时, 实际上并不是把该字符的字型放到内存中, 而是把该字符的ASCⅡ码值放到存储单元中, 每个字符的ASCⅡ码值详见附录A。打印字符型变量时, 如果以字符形式打a 印,那么计算机会到 ASCⅡ码表中查找字符型变量的ASCⅡ码值, 查到对应的字符后会显示对应的字符,
如图所示。这样, 字符型数据和整型数据之间就可以通用。字符型数据既可以以字符形式输出, 又可以以整数形式输出, 还可以通过运算获取想要的各种字符, 请看下面例子。

#include <stdio.h>
int main()
{
char c='A';
printf("%c\n",c+32);
printf("%d\n",c);
}
a
65
对于字符型变量, 无论是赋 ASCII码值还是赋字符, 使用%c 打印输出时得到的都是字符,使用%d打印输出时得到的都是ASCⅡ码值。将小写字母转换为大写字母时,由课件最后的ASCII码表发现小写字母与大写字母的差值为 32, 因此将c减去32 就可以得到大写字母A。
2.8字符串型常量
字符串型常量是由一对双引号括起来的字符序列。 例如, “How do you do.”、”CHINA”、”a”和”$123.45”是合法的字符串型常量, 我们可用语句 printf(“How do you do.”)输出一个字符串。但要注意的是, ‘a’是字符型常量, 而”a”是字符串型常量, 二者是不同的.
例如, 如果先用语句 char c定义字符型变量c, 后令c=”a″或c=”CH‖NA”,, 那么这样的赋值都是非法的, 原因是不可以将字符串型常量赋值给字符型变量. C语言中没有定义字符串型变量的关键字, 介绍字符数组时我们将详细讲解如何存放字符串。
C 语言规定, 在每个字符串型常量的结尾加一个字符串结束标志, 以便系统据此判断字符串是否结束。C语言规定以字符’\0’作为字符串结束标志。
例如, 字符串型常量”CHINA”在内存中的存储结果如下图所示, 它占用的内存单元不是5个字符, 而是6个字符, 即大小为6字节, 最后一个字符为’\0’。然而, 在输出时不输出’\0’, 因为’\0’无法显示。

字符串型常量”CHINA”在内存中的存储结果
2.9混合运算
类型强制转换场景:
整型数进行除法运算结果为小数,那么储存浮点数时一定要进行强制类型转换
#include <stdio.h>
//强制类型转换
int main() {
int i=5;
float f=i/2;//这里做的是整型运算,因为左右操作数都是整型
float k=(float)i/2;//(float)i 将i从整型转换为浮点型,结果是5.0然后执行5.0/2,浮点型运算,结果是2.5
printf("%f\n",f);
printf("%f\n",k);
return 0;
}
2.10 printf函数
printf 函数可以输出各种类型的数据,包括整型、浮点型、字符型、字符串型等,实际原理是 printf 函数将这些类型的数据格式化为字符串后, 放入标准输出缓冲区, 然后将结果显示到屏幕上。
#include <stdio.h>
int printf(const char *format, …);
printf 函数根据format 给出的格式打印输出到stdout(标准输出) 和其他参数中。字符串格式(format) 由两部分组成: 显示到屏幕上的字符和定义 printf 函数显示的其他参数. 我们可以指定一个包含文本在内的format字符串, 也可以是映射到 printf 的其他参数的“特殊”字符, 如下列代码所示:
int age = 21;
printf("Hello %s, you are %d years old\n","Bob", age);
代码输出如下
Hello Bob, you are 21 years old
其中, %s表示在该位置插入首个参数(一个字符串), %d 表示第二个参数(一个整数) 应该放在哪里. 不同的%codes表示不同的变量类型, 也可以限制变量的长度, printf 函数的具体代码格式如下表所示。
printf 函数的具体代码格式
| 代码 | 格式 |
|---|---|
| %c | 字符 |
| %d | 带符号整数 |
| %f | 浮点数 |
| %s | 一串字符 |
| %u | 无符号整数 |
| %x | 无符号十六进制数,用小写字母 |
| %X | 无符号十六进制数,用大写字母 |
| %p | 一个指针 |
| %% | 一个%号 |
位于%和格式化命令之间的一个整数被称为最小字段宽度说明符, 通常会加上空格来控制格式.
用%f 精度修饰符指定想要的小数位数,例如, %5.2f会至少显示5位数字并带有 2位小数的浮点数.
用%s精度修饰符简单地表示一个最大的长度, 以补充句点前的最小字段长度。
printf 函数的所有输出都是右对齐的, 除非在%符号后放置了负号。例如, %-5.2f 会显示5位字符、2位小数位的浮点数并且左对齐。
例子
#include <stdio.h>
int main() {
int age=21;
printf("Hello %s, you are %d years old\n", "Bob", age);
int i=10;
float f=96.3;
printf("student number=%-3d,score=%5.2f\n",i,f);//默认是右对齐,加一个负号代表左对齐
i=100;
f=98.21;
printf("student number=%3d,score=%5.2f\n",i,f);
return 0;
}
Hello Bob, you are 21 years old
student number=10 ,score=96.30
student number=100,score=98.21
2.11整型常量的不同进制表示
计算机中只能存储二进制数, 即0和1, 而在对应的物理硬件上则是高、低电平. 为了更方便地观察内存中的二进制数情况, 除我们正常使用的十进制数外, 计算机还提供了十六进制数和八进制数.
在计算机中, 1字节为8位, 1位即二进制的1位, 它存储0或1, int 型常量的大小为4字节, 即32位.
设有二进制数 0100 1100 0011 0001 0101 0110 1111 1110, 其最低位是 2的零次方, 代表数值的最高位是2的30次方, 最高位为符号位, 符号位为1时是补码, 将在高级阶段的补码部分讲解.
上面的二进制数对应的八进制数是 011414253376 ,它以0开头标示,数位的变化范围是0~7.二进数转换为八进制数的方式是, 对应的二进制数每 3位转换为1位八进制数. 首先将上面的二进制数按每 3位隔开, 得到 01 001 100 001 100 010 101 011 011 111 110, 然后每3位对应0~7范围内的数进行对应转换, 得到八进制数 011414253376 . 由于实际编程时, 识别八进制数时前面需要加0, 所以在前面加了一个0.
上面的二进制数对应的十六进制数是0x4C3156FE,它以0x开头标示,数位的变化范围是0 ~9和A~F, 其中A代表 10, F代表 15, 对应的二进制数每4位转换为1位十六进制数.十六进制在观察内存时需要频繁使用.
上面的二进制数对应的十进制数是 1278301950,具体计算需要以2的幂次相加依次来计算,是2^1^+2^2^+2^3^+⋯+2^30^来实现(为1的位置就需要2的幂次, 为零不需要)
目前我们执行到语句 int i=123, 变量 i会在内存上被分配空间, 大小为4字节,打开内存视图 其中i的值变为7b(我们以十六进制方式查看内存), 其十进制值为 7×16+11=123。i的值是 0x0000007b。为什么显示结果为 7b 00 00 00 呢?原因是英特尔的 CPU 采用了小端方式进行数据存储, 因此低位在前、高位在后.
#include <stdio.h>
int main() {
int i=0x7b;
printf("%d\n",i);//十进制输出
printf("%o\n",i);//八进制
printf("%x\n",i);//十六进制
return 0;
}
123
173
7b
二进制转换:
那么十进制数123转换为二进制数,方法是让123不断地除以2,并把余数写在右边,把商写在下方, 直到商为0, 然后逆序写出所有余数, 即可得到转换后的二进制数1111011, 详细过程如下图所示。对应的十六进制数为 7b, 十进制数转换为十六进制数的方式是除以16, 十进制数转换为八进制数的方式是除以8

2.12 scanf函数读取标准输入
2.12.1 scanf原理
C 语言未提供输入/输出关键字, 其输入和输出是通过标准函数库来实现的。 C语言通过scanf 函数读取键盘输入, 键盘输入又被称为标准输入, 当 scanf 函数读取标准输入时, 如果还没有输入任何内容, 那么scanf函数会被卡住(专业用语为阻塞) , 下面来看一个例子。
#include <stdio.h>
//scanf用来读取标准输入,scanf把标准输入内的内容,需要放到某个变量空间里,因此变量必须取地址
//scanf会阻塞,是因为标准输入缓冲区是空的
int main() {
int i;
char c;
float f;
scanf("%d",&i);
printf("i=%d\n",i);//把标准缓冲区中的整型数读走了
//flush(stdin);//清空标准输入缓冲区
scanf("%c",&c);
printf("c=%c\n",c);//输出字符变量c
// scanf("%f",&f);
// printf("f=%f\n",f);
return 0;
}
123
i=123
c=
为什么第二个scanf 函数不会被阻塞呢是因为第二个 scanf函数读取了缓冲区中的**’\n’**, 即 scanf(“%c”,&c)实现了读取, 打印其实输出了换行, 所以不会阻塞。
行缓冲: 在这种情况下, 当在输入和输出中遇到换行符时, 将执行真正的I/O 处理操作,这时, 我们输入的字符先存放到缓冲区中, 等按下回车键换行时才进行实际的I/O 操作。典型代表是标准输入缓冲区 (stdin) 和标准输出缓冲区(stdout) , printf 使用的是 stdout.
如上面的例子所示,我们向标准输入缓冲区中放入的字符为’20\n’,输入’\n’(回车) 后, scanf函数才开始匹配, scanf函数中的%d匹配整型数20, 然后放入变量i中,接着进行打印输出, 这时’\n’仍然在标准输入缓冲区(stdin) 内, 如果第二个scanf函数为 scanf(“%d”,&i), 那么依然会发生阻塞, 因为scanf函数在读取整型数、浮点数、字符串(后面介绍数组时讲解字符串) 时,会忽略’\n’(回车符) 、空格符等字符(忽略是指 scanf函数执行时会首先删除这些字符, 然后再阻塞) . scanf 函数匹配一个字符时, 会在缓冲区删除对应的字符。 因为在执行scanf(“%c”,&c)语句时, 不会忽略任何字符, 所以scanf(“%c”,&c)读取了还在缓冲区中残留的’\n’.
2.12.1 多种数据类型混合输入
当我们让 scanf函数一次读取多种类型的数据时, 对于字符型数据要格外小心, 因为当一行数据中存在字符型数据读取时, 读取的字符并不会忽略空格和’\n’(回车符) , 所以使用方法如下例所示。编写代码时, 我们需要在**%d与%c之间加入一个空格,输入格式和输出效果如下, scanf函数匹配成功了4个成员, 所以返回值为4,我们可以通过返回值来判断 scanf函数匹配成功了几个成员**, 中间任何有一个成员匹配出错, 后面的成员都会匹配出错。
#include <stdio.h>
//scanf一次读多种数据类型
int main() {
int i,ret;
float f;
char c;
ret=scanf("%d %c%f",&i,&c,&f);//ret是指scanf匹配成功的个数
printf("i=%d,c=%c,f=%5.2f\n",i,c,f);
return 0;
}
1 c 1.1
i=1,c=c,f= 1.10